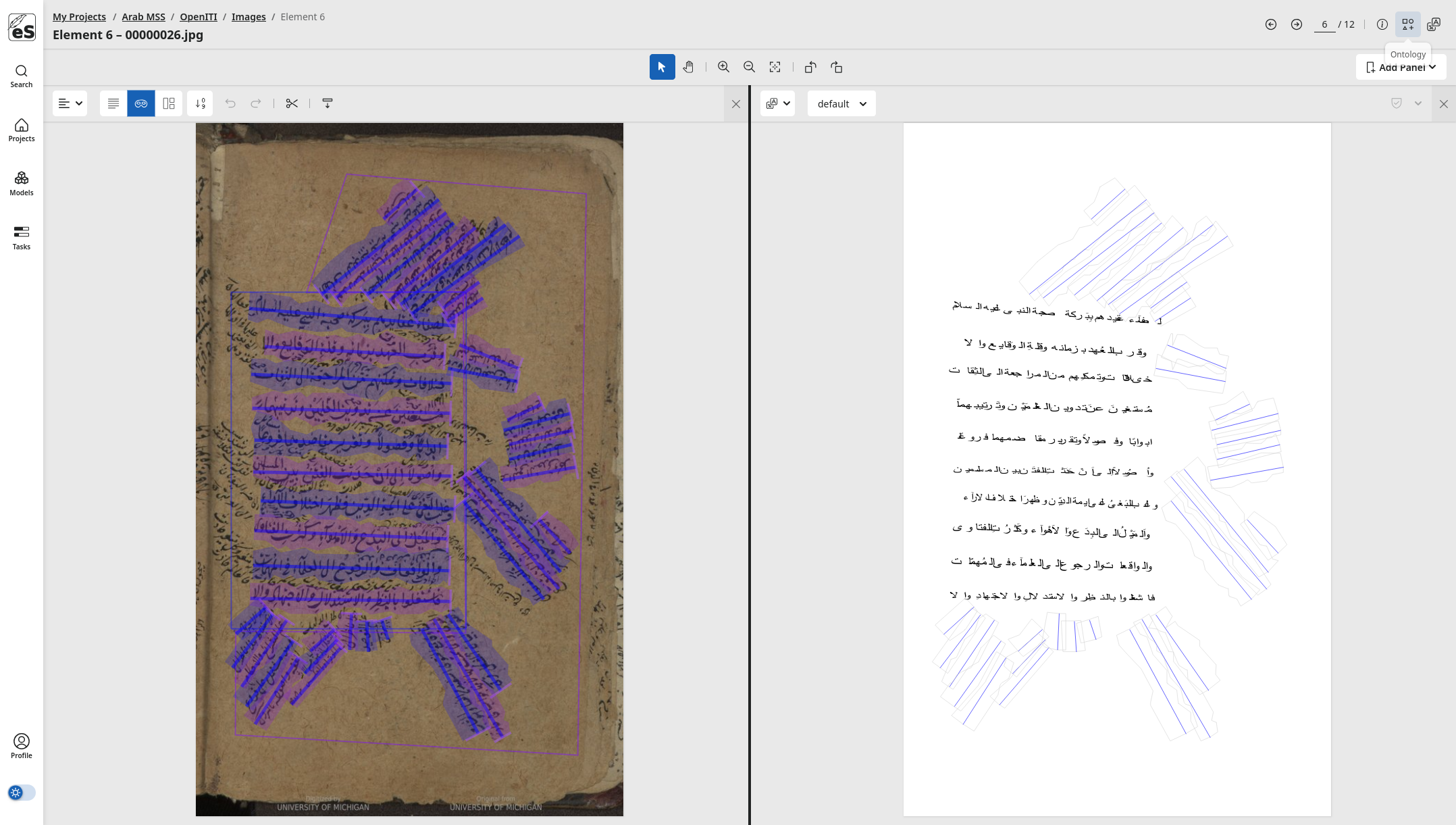
eScriptorium is powered by kraken, a versatile machine-learning engine designed to handle the full spectrum of written history. Whether you are digitizing early printed books, handwritten archival records, or ancient inscriptions on stone, our platform provides the tools to extract not just text, but meaning.
Precision Text Transcription
Standard OCR tools often struggle outside of modern print. eScriptorium is built to handle the variability of human expression across all mediums:
- Print & Incunabula: Handle rare typefaces, historical fonts, and variable inking common in early modern printing.
- Handwriting: Navigate the complexities of cursive, shorthand, and scribal abbreviations with high fidelity.
- Script Agnostic: Capable of processing any writing system, from Medieval Latin and Greek to Hebrew, Arabic, and Cyrillic.
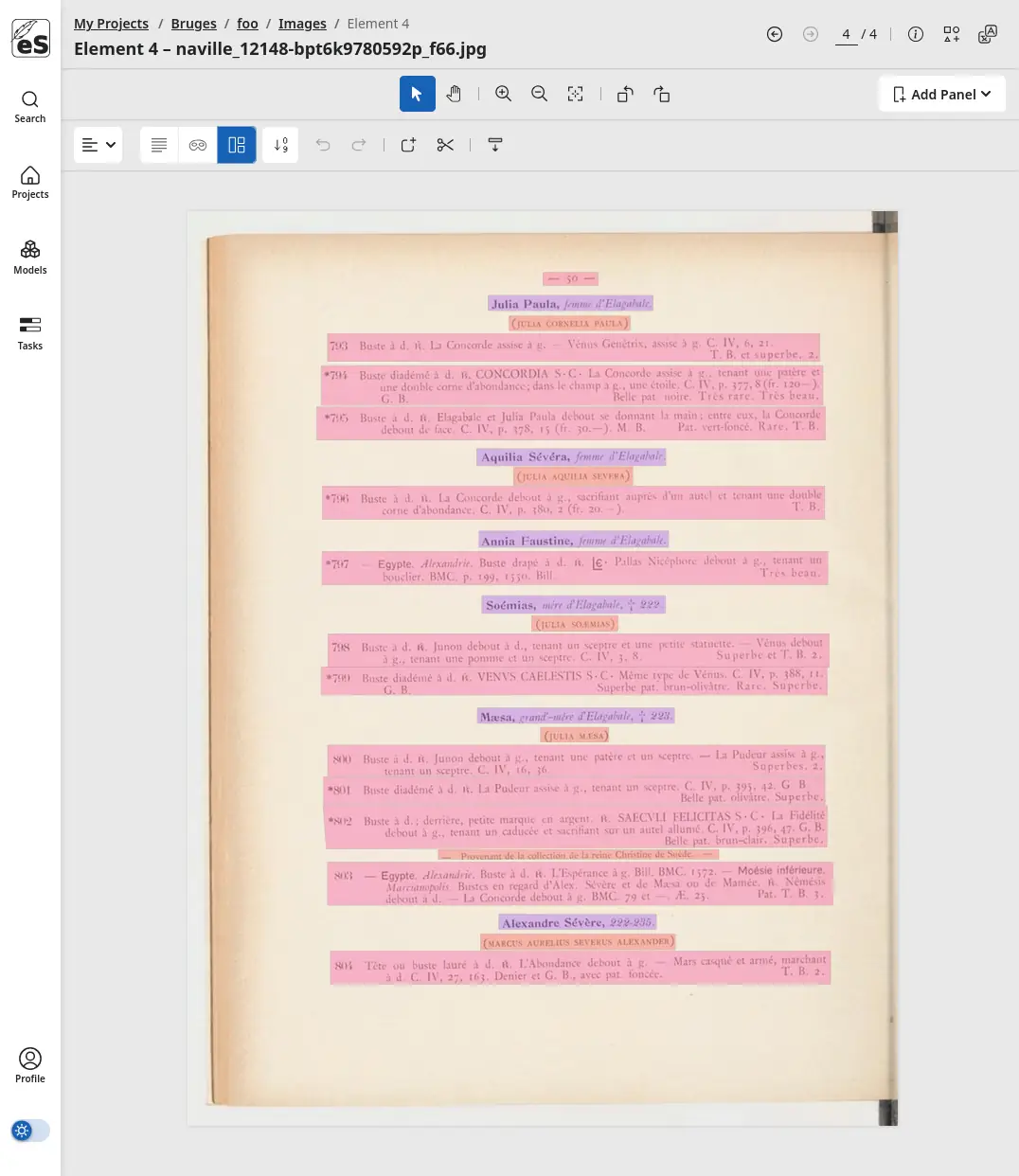
Semantic Layout Analysis
A page is more than a string of characters. eScriptorium can perform advanced layout analysis to deconstruct the geometry of your document, creating rich, structured data outputs.
- Region Segmentation: Automatically identify and classify page elements like main text, marginalia, headers, footers, and captions.
- Reading Order: Define the logical flow of the text.
- Baselines: Accurately detect text lines even when they are curved, skewed, or interlinear.
Jumpstart Your Project
You don’t always need to start from scratch.
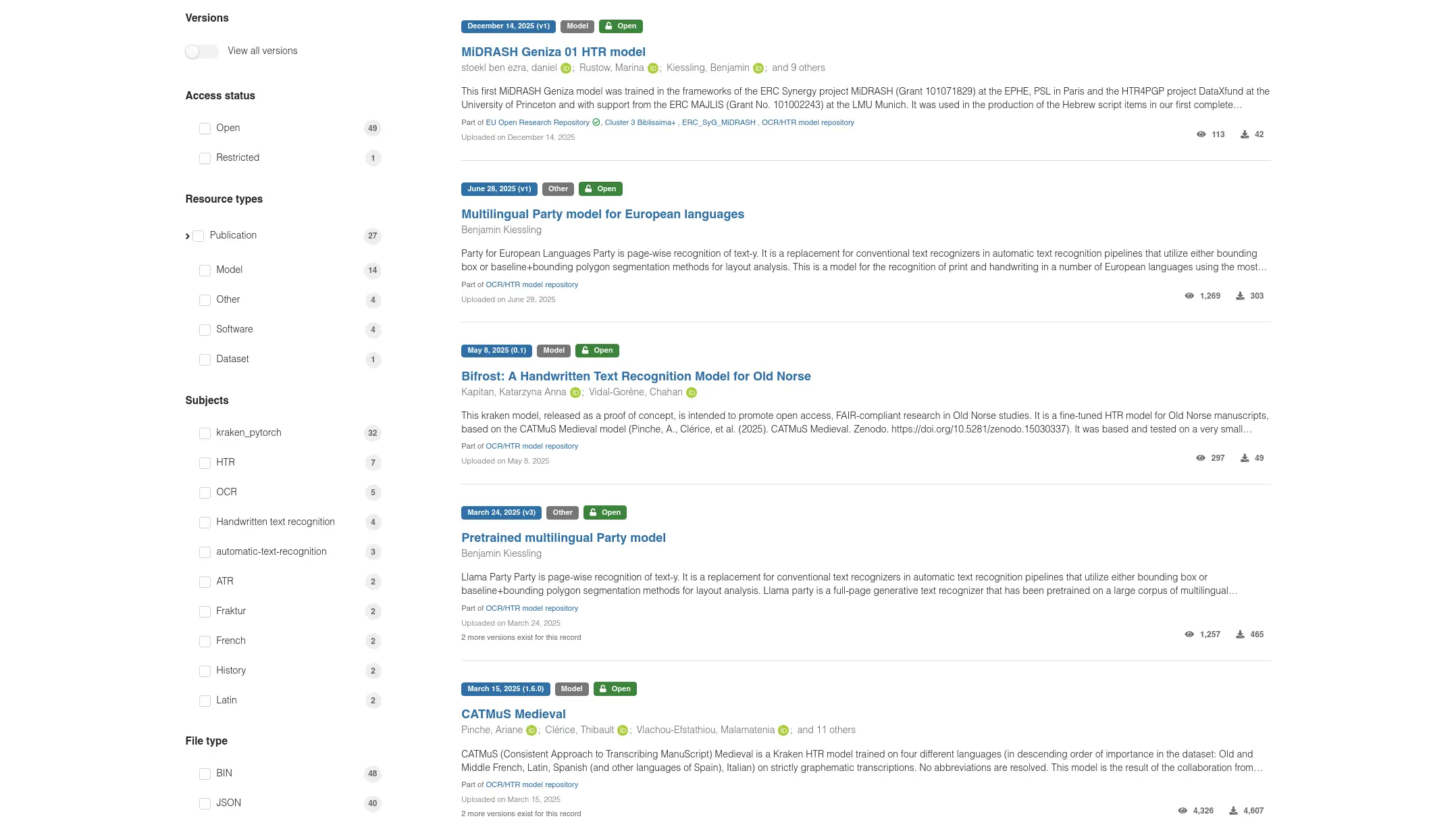
Explore the Model Ecosystem: Access over 50 open-source models in our Zenodo community, ranging from generalized models for Medieval Latin and Hebrew manuscripts to specialized models for particular hands.
These models are ready to be used as-is for immediate results, or can serve as a robust foundation for fine-tuning on your own specific documents — saving you hours of manual transcription and training time!